Процесс сбора ядра был стандартный. Каждое направление прорабатывалось как отдельный проект:
- Сначала сбор базовых маркеров по каждой категории – слов, по которым производилась выгрузка. Первый этап всегда – мозговой штурм.
- Затем анализировали конкурентов из выдачи, дополняли список их запросами
- Далее изучили поисковые подсказки и эхо (правая колонка) wordstat
- Все это сгруппировали в единый список и очистили от нецелевых фраз.
Для выгрузки использовали два сервиса. Сначала Букварикс – он позволяет быстро проанализировать нишу на объем трафика, составить картину об интересах пользователей. Основной его минус – невозможно собрать частоты [!] с фиксацией порядка слов в фразе.
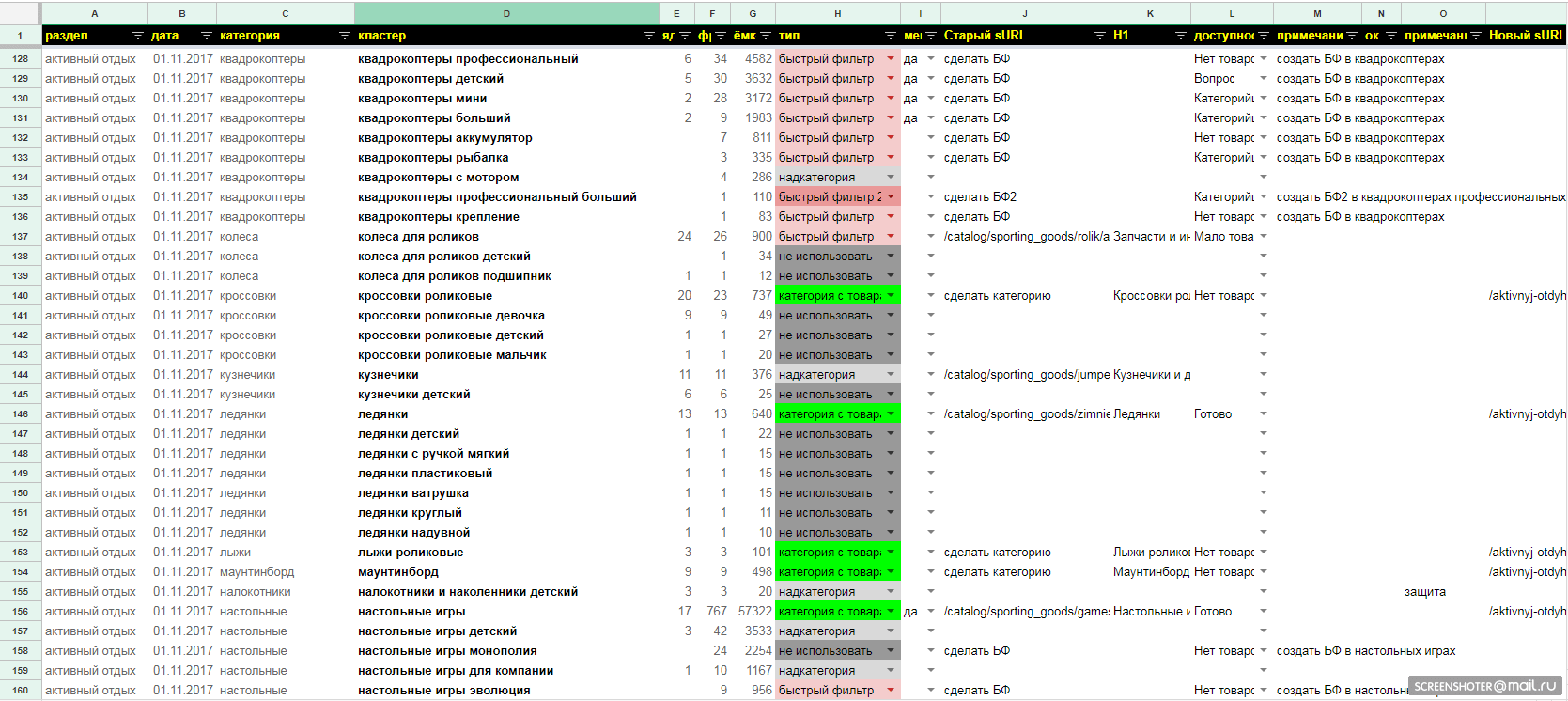
С помощью собственной разработки – оффлайн сервиса, который может за рекордно короткие сроки сделать кластеризацию ядра, мы сэкономили до 5 суток работы, и выделили основные категории на основе частотного словаря по запросам.
После чистки от информационных и нецелевых запросов мы собрали частоту для оставшихся фраз Кейколлектором.
«Мы неоднократно замечали, что сервисы для сбора запросов не всегда дают корректную информацию. Keycollector хорош, но работает долго и теряет часть важных коммерческих запросов из-за ограниченности функционала по объему выгрузки. Поэтому приняли решение использовать 2 сервиса, а на основе их данных выводить средний показать – «емкость». Это давало более объективную картину.»